 Digital Commons Help Center
Digital Commons Help CenterHow Can We Help?
Digital Commons Harvesting Tool: Automatically Populating the IR with Faculty RecordsDigital Commons Harvesting Tool: Automatically Populating the IR with Faculty Records
DC Harvesting Tool Overview
The Digital Commons Harvesting Tool featuring integration with Scopus, Pure, ORCID, PubMed, and Sherpa-Romeo automates many time-consuming faculty publication workflow steps to populate your IR more comprehensively. By harnessing data from multiple APIs, the tool can greatly streamline the process required to locate, assess, and deduplicate faculty records and upload them to Digital Commons (DC).
Adding faculty publications can fulfill core institutional goals for the IR—by providing a service to faculty, showcasing research discoveries, representing an institution’s scholarly outputs, and helping to reach open access targets. However, typical paths to find and ingest faculty publications include many, laborious manual steps for each record.
With the DC Harvesting Tool, you can automate the following steps for a more efficient workflow regardless of whether your IR hosts metadata-only records or requires a full-text file/copy with every record:
- Find all your institution’s works
- Identify OA content
- Map and prepopulate high-quality metadata for upload, plus import full-texts from Pure
- Check for duplicate records already in your IR
- Check permissions for multiple journals at a time
Applications of the Harvesting Tool
The Harvesting Tool is particularly helpful to institutions who are:
- Populating a brand new, or recently migrated IR
- Standing up faculty publication workflows for the first time
- Seeking even more efficiency with existing faculty publication workflows
- Looking to improve departments’ and faculty members’ engagement with the IR
- Seeking improved ways to support the research enterprise on campus
- Wanting to identify more open access content to host
- Wishing to extend content visibility from Pure while avoiding duplication
Have questions or need assistance before getting started? See our Contact Us page for how to contact Consulting Services.
Getting Started
Administrators of Digital Commons with appropriate permissions can access the DC Harvesting Tool via their My Account page. Access to some harvesting sources is included for Digital Commons subscribers, while others require that you add or already have a subscription to that service. Please see the specifics below for each harvesting source.
ORCID: As a Digital Commons subscriber, you may access all publicly available records from each matching ORCID profile. This is accessible within the DC Harvesting Tool regardless of whether or not your institution is an ORCID institutional member.
PubMed: PubMed data is accessible to all users of the DC Harvesting Tool.
Pure: Pure data is available if your institution also subscribes to Pure, with a one-time setup using an API key that you generate—refer to the Digital Commons Harvesting Tool: Step-by-Step Guide for details.
Scopus: Access to Scopus data in the DC Harvesting Tool is available to Scopus subscribers with a one-time setup or as an add-on module. Scopus is a leading subscription abstract and index database. It has extensive breadth and coverage with close to 80 million records from ~25,000 journals, books and book series, conference proceedings, and trade publications across all disciplines. Using robust machine learning algorithms, it delivers high-quality metadata with disambiguation at author and institution levels.
Sherpa-Romeo: A Sherpa-Romeo journal permissions checking option is available to all users when harvesting from any source.
How It Works
When you perform a search, the Harvesting Tool uses the API from your selected source—Scopus, Pure, ORCID, or PubMed—to locate relevant author and institutional records, which you can then easily export in prepopulated batch upload spreadsheets for ingest into DC.
Below is an overview of the basic workflow when using the Harvesting Tool. See the Digital Commons Harvesting Tool: Step-by-Step Guide for detailed instructions, including tips for preparation.
1. Select a source and search records
ORCID and PubMed appear as sources in the Harvesting Tool by default. Pure will appear as an additional option if your institution is a joint DC-Pure customer and you’ve provided a Pure API key as described in the step-by-step guide. Scopus appears for subscribers who have added the Scopus module.
Search options vary depending on the source selected and are flexible to work with the information you have available (ORCID search currently only supports searching by ORCID ID.)
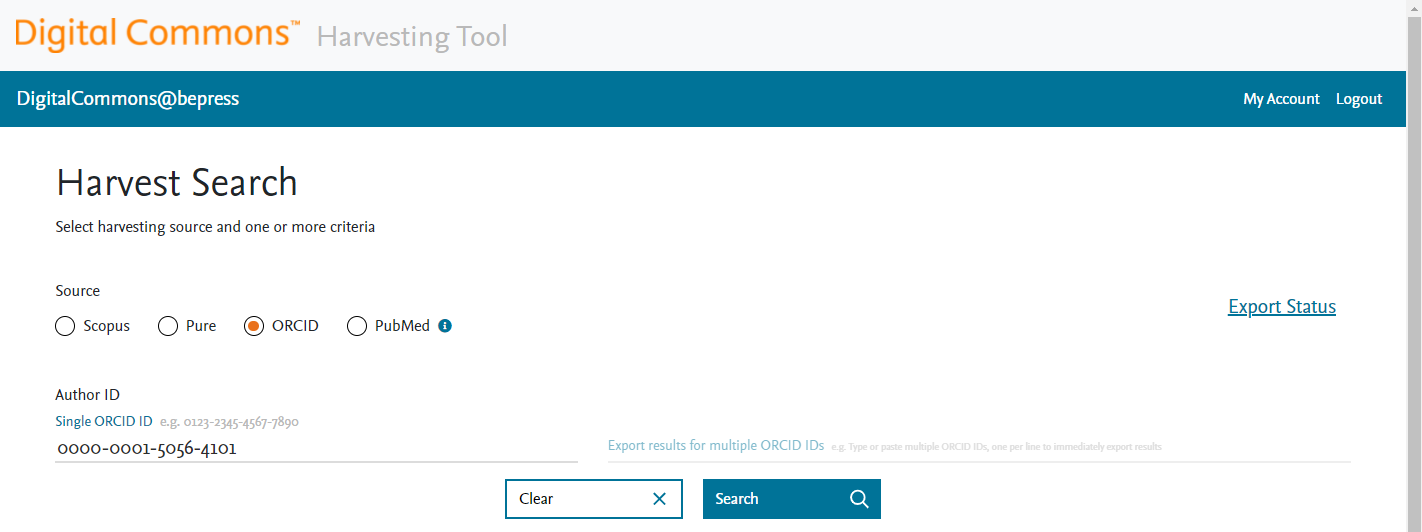
2. Review search results
Confirm results are relevant and have the correct author and other metadata. Narrow down or broaden your search if needed to refine results.
When harvesting from Scopus, an Open Access flag indicates where a work was originally published in open access form, and additional labels show specific OA categories that may apply to a work.
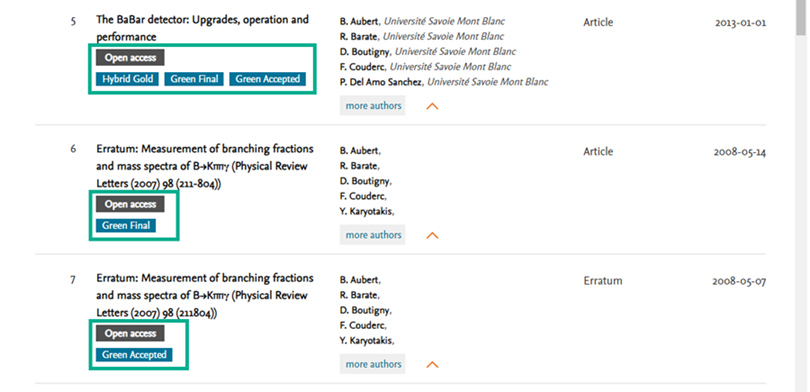
3. Export records to a prepopulated spreadsheet
When search results contain the records of interest, export a spreadsheet containing the source metadata automatically mapped to the schema of the target publication/collection in the IR. (Pure export spreadsheets will, in addition, contain full-texts where available.)

You may choose to include journal permissions information from Sherpa-Romeo with detailed publisher policies, conveniently listed with the corresponding works in your exported spreadsheet.

Export options also include a duplication check function that identifies likely duplicates either in the selected DC publication or in all DC publications of a given type.
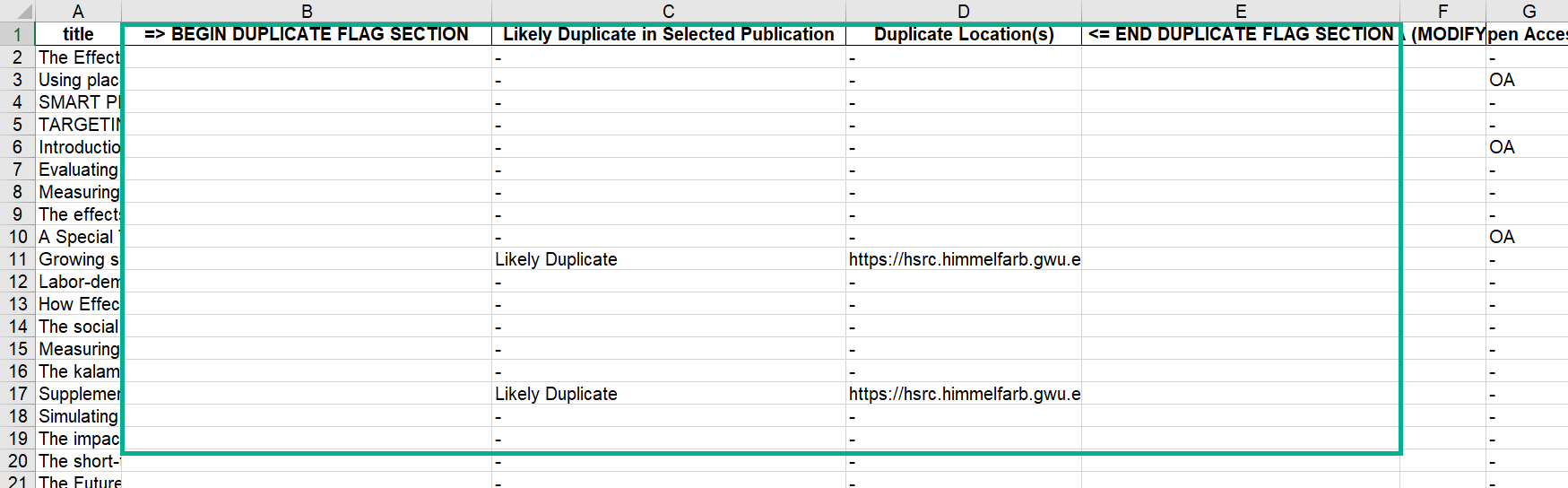
The spreadsheet format allows you to review, add, and fine-tune the metadata, if needed, before importing to DC. Depending on whether your IR hosts metadata-only records or requires full-text copies with records, the spreadsheet format also allows you to have a “worklist document” to then seek faculty/researcher approvals, further check publisher rights and permissions as required, and request/obtain permitted full-text copies of works. Results from those optional steps can then be incorporated into the batch upload spreadsheet.
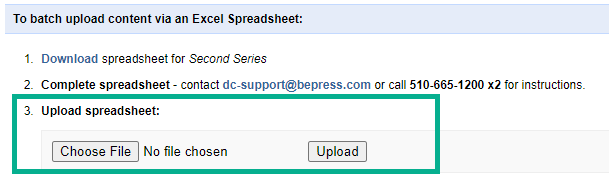
4. Upload the spreadsheet using DC batch import
Import records into the selected DC publication/collection using that publication’s batch import tool, skipping straight to the “Upload spreadsheet” step.
For detailed instructions on using the DC Harvesting Tool, please see the step-by-step guide, available below. If you have any questions or would like recommendations on how the Harvesting Tool can help with your institution’s specific needs, please contact your consultant for more information.