We sometimes find that the most valuable features in Digital Commons are not necessarily the most obvious– in this instance, we are talking about the automatically generated PDF cover pages. At last check, we found that around 80% of all visitors to Digital Commons repository content landed directly on the PDF from a Google or Google Scholar search, meaning that these cover pages are quite possibly the most viewed real estate in your IR.
So what value do cover pages bring? As much as 5% of traffic to a Digital Commons repository comes from the active links on the cover pages, so they are a significant source of referral traffic for your repository. Want more? Google Scholar crawlers index articles with cover page pages more quickly and accurately because of well formatted and standardized bibliographic metadata: stamped cover pages help with discoverability.
As far as we are concerned, however, the greatest value of the institutionally branded cover pages is that they provide context to readers who come from Google and don’t know whether or not to “trust” this source. To illustrate this point, below is a blog post that we recently ran across, written by a scholar who found himself precisely in that situation. If you have ever wondered what a scholar thinks when she lands on your cover pages, this blog serves as an excellent proxy. Emphasis is the author’s.
“Raising visibility of repository contents for internet users”
By Pablo de Castro
Nowadays it has become commonplace to criticize institutional repositories for their lack of content specificity: you can’t tell what version of the document is being made available, there is a lot of materials of insufficient quality in there, everything’s mixed up, etc. When one has devoted a good part of one’s professional career to develop such useful resources, this criticism is a bit painful to take. It’s true IRs have weaknesses, even lots of weaknesses, but there is quite a number of people across the world working to solve them and to improve IR content quality and description. And IRs do have a decent collection of advantages alright – that should also be acknowledged to be fair. I shall now highlight one of those advantages, incidentally not even the most important one.
This morning I was looking for some bibliography on research data management performed via institutional repositories for a report I’m currently working at. So I googled research data management institutional repositories and this is what I got:
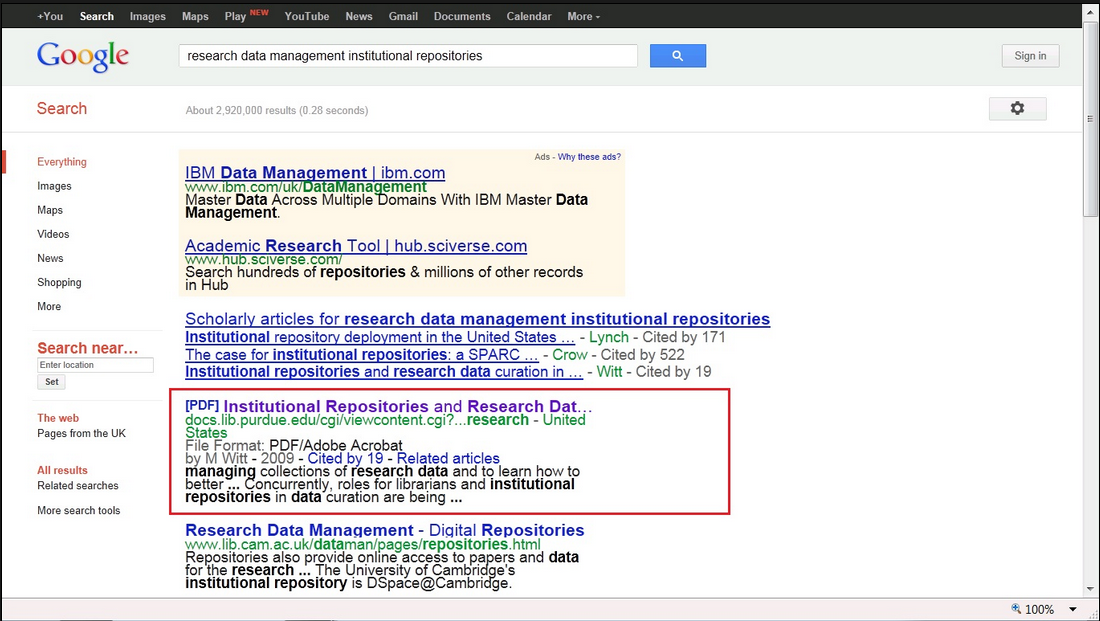
The reference that caught my attention was of course the one with the red square around it: seems to be called Institutional Repositories and Research Data and seems to be coming from Purdue University Library in the US, although the exact source is difficult to tell from the URL there: docs.lib.purdue.edu/cgi/viewcontent.cgi?…research.
When I opened it I was simply delighted to find this “Institutional Repositories and Research Data Curation in a Distributed Environment” report by Michael Witt and I was also quite amazed to see its publication date – there are clearly several speeds out there in research data management implementation.

When trying to figure out how to cite this report I suddenly became aware of the document head: Purdue University, Purdue ePubs, Libraries research Publications, Purdue Libraries. Had this document by any chance been retrieved from an Institutional Repository? So I checked the footnote: “This document has been made available through Purdue e-Pubs, a service of the Purdue University Libraries. Please contact epubs@purdue.edu for additional information”. I was simply ecstatic.

I remember having had this discussion about inserting document covers into repository contents more than once when I worked as IR manager. The arguments for not doing it were always the same: we do have too many documents in the repository by now to start re-processing them all and we should instead focus on getting even more of them filed into the IR. These are quite good arguments indeed, but it’s the kind of argument that lead to the issues we’re now bitterly complaining about. It’s a fact that IRs can be properly managed, that a great improvement in description standards has taken place and that there is a still a long way to go until we reach a consensus on a description standard that can please researchers. But not too many IRs that I know of have implemented this rather simple strategy of providing their documents a cover so that users will be able to identify their source and subsequently give it some credit. Of course there are lots of exceptions to this -if you’re in the UK or the US you will say that’s something every average repository has already cared for, see for instance this example from Enlighten repository in Glasgow or this other one from the LSE repo in London– but I’d say most IRs, even top-ranked ones, lack this small but very useful feature – since given the joint Open Access repository content figures nowadays, the repository+google/googlescholar combination is pretty much unbeatable. I would even dare to suggest some kind of harmonised international seal for identifying reliable research content coming from an institutional repository from their very cover – so that the user will be able to give credit where credit is due.
Let me finish this piece of advocacy with a recommendation to read the abovementioned Purdue University Library report to any colleague interested in potential opportunities for starting out research data management initiatives from the University Library.”